LangChain¶
Here we have some code snippets that help compare a vanilla code implementation with LangChain and Apache Hamilton.
LangChain’s focus is on hiding details and making code terse.
Apache Hamilton’s focus instead is on making code more readable, maintainable, and importantly customizeable.
So don’t be surprised that Apache Hamilton’s code is “longer” - that’s by design. There is also little abstraction between you, and the underlying libraries with Apache Hamilton. With LangChain they’re abstracted away, so you can’t really see easily what’s going on underneath.
Rhetorical question: which code would you rather maintain, change, and update?
A simple joke example¶
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_invoke.py
from typing import List
import openai
def llm_client() -> openai.OpenAI:
return openai.OpenAI()
def joke_prompt(topic: str) -> str:
return f"Tell me a short joke about {topic}"
def joke_messages(joke_prompt: str) -> List[dict]:
return [{"role": "user", "content": joke_prompt}]
def joke_response(llm_client: openai.OpenAI,
joke_messages: List[dict]) -> str:
response = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=joke_messages,
)
return response.choices[0].message.content
if __name__ == "__main__":
import hamilton_invoke
from hamilton import driver
dr = (
driver.Builder()
.with_modules(hamilton_invoke)
.build()
)
dr.display_all_functions("hamilton-invoke.png")
print(dr.execute(["joke_response"],
inputs={"topic": "ice cream"}))
|
from typing import List
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
def call_chat_model(messages: List[dict]) -> str:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
return response.choices[0].message.content
def invoke_chain(topic: str) -> str:
prompt_value = prompt_template.format(topic=topic)
messages = [{"role": "user", "content": prompt_value}]
return call_chat_model(messages)
if __name__ == "__main__":
print(invoke_chain("ice cream"))
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
if __name__ == "__main__":
print(chain.invoke("ice cream"))
|
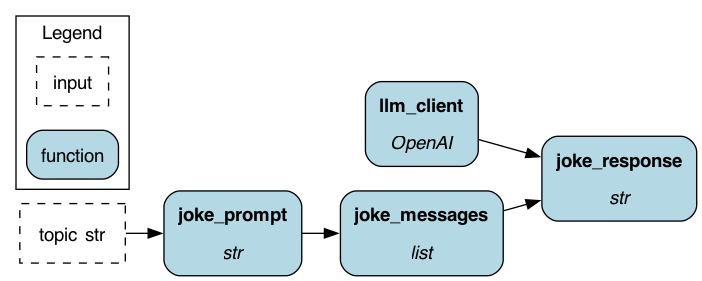
The Hamilton DAG visualized.¶
A streamed joke example¶
With Apache Hamilton we can just swap the call function to return a streamed response. Note: you could use @config.when to include both streamed and non-streamed versions in the same DAG.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_streamed.py
from typing import Iterator, List
import openai
def llm_client() -> openai.OpenAI:
return openai.OpenAI()
def joke_prompt(topic: str) -> str:
return (
f"Tell me a short joke about {topic}"
)
def joke_messages(
joke_prompt: str) -> List[dict]:
return [{"role": "user",
"content": joke_prompt}]
def joke_response(
llm_client: openai.OpenAI,
joke_messages: List[dict]) -> Iterator[str]:
stream = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=joke_messages,
stream=True
)
for response in stream:
content = response.choices[0].delta.content
if content is not None:
yield content
if __name__ == "__main__":
import hamilton_streaming
from hamilton import driver
dr = (
driver.Builder()
.with_modules(hamilton_streaming)
.build()
)
dr.display_all_functions(
"hamilton-streaming.png"
)
result = dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
for chunk in result["joke_response"]:
print(chunk, end="", flush=True)
|
from typing import List
from typing import Iterator
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
def stream_chat_model(
messages: List[dict]) -> Iterator[str]:
stream = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
stream=True,
)
for response in stream:
content = response.choices[0].delta.content
if content is not None:
yield content
def stream_chain(topic: str) -> Iterator[str]:
prompt_value = prompt_template.format(topic=topic)
return stream_chat_model(
[{"role": "user", "content": prompt_value}])
if __name__ == "__main__":
for chunk in stream_chain("ice cream"):
print(chunk, end="", flush=True)
|
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}"
)
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
if __name__ == '__main__':
for chunk in chain.stream("ice cream"):
print(chunk, end="", flush=True)
|
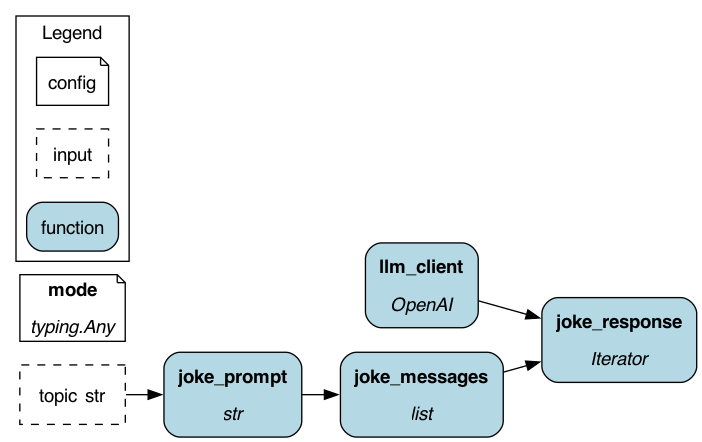
The Hamilton DAG visualized.¶
A “batch” parallel joke example¶
In this batch example, the joke requests are parallelized. Note: with Apache Hamilton you can delegate to many different backends for parallelization, e.g. Ray, Dask, etc. We use multi-threading here.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_batch.py
from typing import List
import openai
from hamilton.execution import executors
from hamilton.htypes import Collect
from hamilton.htypes import Parallelizable
def llm_client() -> openai.OpenAI:
return openai.OpenAI()
def topic(
topics: list[str]) -> Parallelizable[str]:
for _topic in topics:
yield _topic
def joke_prompt(topic: str) -> str:
return f"Tell me a short joke about {topic}"
def joke_messages(
joke_prompt: str) -> List[dict]:
return [{"role": "user",
"content": joke_prompt}]
def joke_response(llm_client: openai.OpenAI,
joke_messages: List[dict]) -> str:
response = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=joke_messages,
)
return response.choices[0].message.content
def joke_responses(
joke_response: Collect[str]) -> List[str]:
return list(joke_response)
if __name__ == "__main__":
import hamilton_batch
from hamilton import driver
dr = (
driver.Builder()
.with_modules(hamilton_batch)
.enable_dynamic_execution(
allow_experimental_mode=True
)
.with_remote_executor(
executors.MultiThreadingExecutor(5)
)
.build()
)
dr.display_all_functions("hamilton-batch.png")
print(
dr.execute(
["joke_responses"],
inputs={
"topics": ["ice cream",
"spaghetti",
"dumplings"]
}
)
)
# can still run single chain with overrides
# and getting just one response
print(
dr.execute(
["joke_response"],
overrides={"topic": "lettuce"}
)
)
|
from concurrent.futures import ThreadPoolExecutor
from typing import List
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
def call_chat_model(messages: List[dict]) -> str:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
return response.choices[0].message.content
def invoke_chain(topic: str) -> str:
prompt_value = prompt_template.format(topic=topic)
messages = [{"role": "user",
"content": prompt_value}]
return call_chat_model(messages)
def batch_chain(topics: list) -> list:
with ThreadPoolExecutor(max_workers=5) as executor:
return list(
executor.map(invoke_chain, topics)
)
if __name__ == "__main__":
print(
batch_chain(
["ice cream", "spaghetti", "dumplings"]
)
)
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
if __name__ == "__main__":
print(
chain.batch(
["ice cream",
"spaghetti",
"dumplings"]
)
)
|
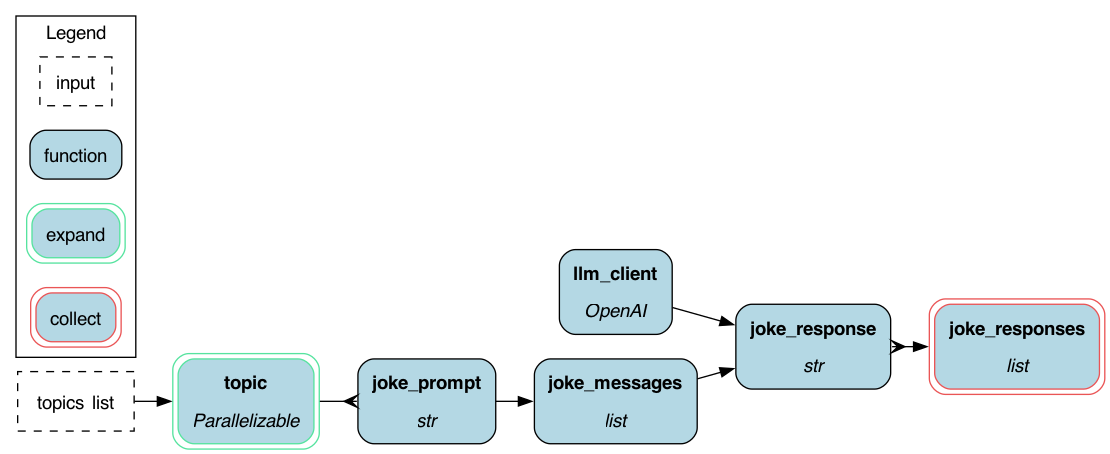
The Hamilton DAG visualized.¶
A “async” joke example¶
Here we show how to make the joke using async constructs. With Apache Hamilton you can mix and match async and regular functions, the only change is that you need to use the async Hamilton Driver.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_async.py
from typing import List
import openai
def llm_client() -> openai.AsyncOpenAI:
return openai.AsyncOpenAI()
def joke_prompt(topic: str) -> str:
return (
f"Tell me a short joke about {topic}"
)
def joke_messages(
joke_prompt: str) -> List[dict]:
return [{"role": "user",
"content": joke_prompt}]
async def joke_response(
llm_client: openai.AsyncOpenAI,
joke_messages: List[dict]) -> str:
response = await (
llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=joke_messages,
)
)
return response.choices[0].message.content
if __name__ == "__main__":
import asyncio
import hamilton_async
from hamilton import base
from hamilton import async_driver
dr = async_driver.AsyncDriver(
{},
hamilton_async,
result_builder=base.DictResult()
)
dr.display_all_functions("hamilton-async.png")
loop = asyncio.get_event_loop()
result = loop.run_until_complete(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
print(result)
|
from typing import List
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
async_client = openai.AsyncOpenAI()
async def acall_chat_model(
messages: List[dict]) -> str:
response = await (
async_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
)
return response.choices[0].message.content
async def ainvoke_chain(topic: str) -> str:
prompt_value = prompt_template.format(
topic=topic
)
messages = [{"role": "user",
"content": prompt_value}]
return await acall_chat_model(messages)
if __name__ == "__main__":
import asyncio
loop = asyncio.get_event_loop()
result = loop.run_until_complete(
ainvoke_chain("ice cream")
)
print(result)
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
if __name__ == "__main__":
import asyncio
loop = asyncio.get_event_loop()
result = loop.run_until_complete(
chain.ainvoke("ice cream")
)
print(result)
|
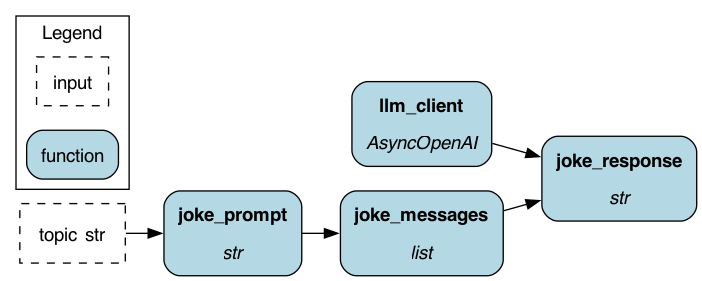
The Hamilton DAG visualized.¶
Switch LLM to completion for joke¶
Here we show how to make the joke switching to a different openAI model that is for completion. Note: we use the @config.when construct to augment the original DAG and add a new function that uses the different OpenAI model.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_completion.py
from typing import List
import openai
from hamilton.function_modifiers import config
def llm_client() -> openai.OpenAI:
return openai.OpenAI()
def joke_prompt(topic: str) -> str:
return f"Tell me a short joke about {topic}"
def joke_messages(
joke_prompt: str) -> List[dict]:
return [{"role": "user",
"content": joke_prompt}]
@config.when(type="completion")
def joke_response__completion(
llm_client: openai.OpenAI,
joke_prompt: str) -> str:
response = llm_client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=joke_prompt,
)
return response.choices[0].text
@config.when(type="chat")
def joke_response__chat(
llm_client: openai.OpenAI,
joke_messages: List[dict]) -> str:
response = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=joke_messages,
)
return response.choices[0].message.content
if __name__ == "__main__":
import hamilton_completion
from hamilton import driver
dr = (
driver.Builder()
.with_modules(hamilton_completion)
.with_config({"type": "completion"})
.build()
)
dr.display_all_functions(
"hamilton-completion.png"
)
print(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
dr = (
driver.Builder()
.with_modules(hamilton_completion)
.with_config({"type": "chat"})
.build()
)
dr.display_all_functions("hamilton-chat.png")
print(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
|
import openai
prompt_template = "Tell me a short joke about {topic}"
client = openai.OpenAI()
def call_llm(prompt_value: str) -> str:
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt_value,
)
return response.choices[0].text
def invoke_llm_chain(topic: str) -> str:
prompt_value = prompt_template.format(topic=topic)
return call_llm(prompt_value)
if __name__ == "__main__":
print(invoke_llm_chain("ice cream"))
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAI
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
llm = OpenAI(model="gpt-3.5-turbo-instruct")
llm_chain = (
{"topic": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
if __name__ == "__main__":
print(llm_chain.invoke("ice cream"))
|
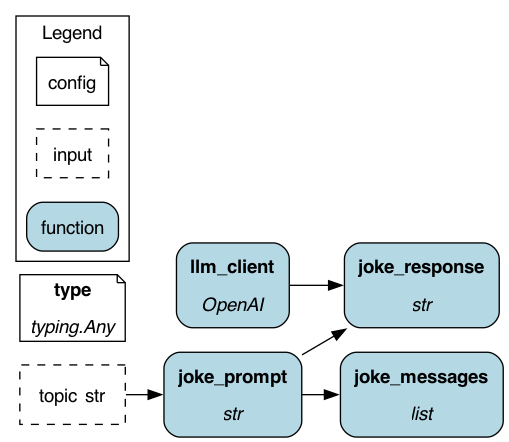
The Hamilton DAG visualized with configuration provided for the completion path. Note the dangling node - that’s normal, it’s not used in the completion path.¶
Switch to using Anthropic¶
Here we show how to make the joke switching to use a different model provider, in this case it’s Anthropic. Note: we use the @config.when construct to augment the original DAG and add a new functions to use Anthropic.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# hamilton_anthropic.py
import anthropic
import openai
from hamilton.function_modifiers import config
@config.when(provider="openai")
def llm_client__openai() -> openai.OpenAI:
return openai.OpenAI()
@config.when(provider="anthropic")
def llm_client__anthropic() -> anthropic.Anthropic:
return anthropic.Anthropic()
def joke_prompt(topic: str) -> str:
return (
"Human:\n\n"
"Tell me a short joke about {topic}\n\n"
"Assistant:"
).format(topic=topic)
@config.when(provider="openai")
def joke_response__openai(
llm_client: openai.OpenAI,
joke_prompt: str) -> str:
response = llm_client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=joke_prompt,
)
return response.choices[0].text
@config.when(provider="anthropic")
def joke_response__anthropic(
llm_client: anthropic.Anthropic,
joke_prompt: str) -> str:
response = llm_client.completions.create(
model="claude-2",
prompt=joke_prompt,
max_tokens_to_sample=256
)
return response.completion
if __name__ == "__main__":
import hamilton_invoke_anthropic
from hamilton import driver
dr = (
driver.Builder()
.with_modules(hamilton_invoke_anthropic)
.with_config({"provider": "anthropic"})
.build()
)
dr.display_all_functions(
"hamilton-anthropic.png"
)
print(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
dr = (
driver.Builder()
.with_modules(hamilton_invoke_anthropic)
.with_config({"provider": "openai"})
.build()
)
print(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
|
import anthropic
prompt_template = "Tell me a short joke about {topic}"
anthropic_template = f"Human:\n\n{prompt_template}\n\nAssistant:"
anthropic_client = anthropic.Anthropic()
def call_anthropic(prompt_value: str) -> str:
response = anthropic_client.completions.create(
model="claude-2",
prompt=prompt_value,
max_tokens_to_sample=256,
)
return response.completion
def invoke_anthropic_chain(topic: str) -> str:
prompt_value = anthropic_template.format(topic=topic)
return call_anthropic(prompt_value)
if __name__ == "__main__":
print(invoke_anthropic_chain("ice cream"))
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatAnthropic
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
anthropic = ChatAnthropic(model="claude-2")
anthropic_chain = (
{"topic": RunnablePassthrough()}
| prompt
| anthropic
| output_parser
)
if __name__ == "__main__":
print(anthropic_chain.invoke("ice cream"))
|
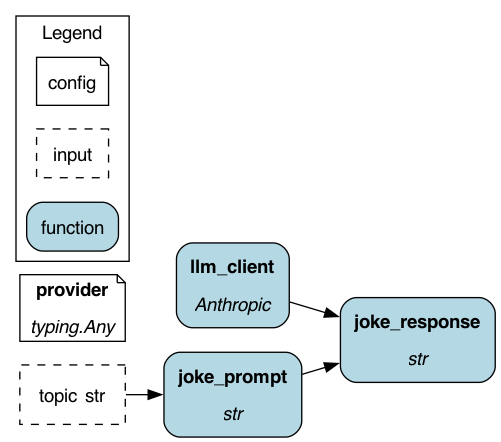
The Hamilton DAG visualized with configuration provided to use Anthropic.¶
Logging¶
Here we show how to log more information about the joke request. Apache Hamilton has lots of customization options, and one out of the box is to log more information via printing.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
# run.py
from hamilton import driver, lifecycle
import hamilton_anthropic
dr = (
driver.Builder()
.with_modules(hamilton_anthropic)
.with_config({"provider": "anthropic"})
# we just need to add this line to get things printing
# to the console; see DAGWorks for a more off-the-shelf
# solution.
.with_adapters(lifecycle.PrintLn(verbosity=2))
.build()
)
print(
dr.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
|
import anthropic
prompt_template = "Tell me a short joke about {topic}"
anthropic_template = f"Human:\n\n{prompt_template}\n\nAssistant:"
anthropic_client = anthropic.Anthropic()
def call_anthropic(prompt_value: str) -> str:
response = anthropic_client.completions.create(
model="claude-2",
prompt=prompt_value,
max_tokens_to_sample=256,
)
return response.completion
def invoke_anthropic_chain_with_logging(topic: str) -> str:
print(f"Input: {topic}")
prompt_value = anthropic_template.format(topic=topic)
print(f"Formatted prompt: {prompt_value}")
output = call_anthropic(prompt_value)
print(f"Output: {output}")
return output
if __name__ == "__main__":
print(invoke_anthropic_chain_with_logging("ice cream"))
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatAnthropic
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
anthropic = ChatAnthropic(model="claude-2")
anthropic_chain = (
{"topic": RunnablePassthrough()}
| prompt
| anthropic
| output_parser
)
if __name__ == "__main__":
import os
os.environ["LANGCHAIN_API_KEY"] = "..."
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# it's hard to customize the logging output of langchain
# so here's their way to try to make money from you!
print(anthropic_chain.invoke("ice cream"))
|
Fallbacks¶
Fallbacks are pretty situation and context dependent. It’s not that hard to wrap a function in a try/except block. The key is to make sure you know what’s going on, and that a fallback was triggered. So in our opinion it’s better to be explicit about it.
Apache Hamilton |
Vanilla |
LangChain |
|---|---|---|
import hamilton_anthropic
from hamilton import driver
anthropic_driver = (
driver.Builder()
.with_modules(hamilton_anthropic)
.with_config({"provider": "anthropic"})
.build()
)
openai_driver = (
driver.Builder()
.with_modules(hamilton_anthropic)
.with_config({"provider": "openai"})
.build()
)
try:
print(
anthropic_driver.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
except Exception:
# this is the current way to do fall backs
print(
openai_driver.execute(
["joke_response"],
inputs={"topic": "ice cream"}
)
)
|
def invoke_chain_with_fallback(topic: str) -> str:
try:
return invoke_chain(topic) # noqa: F821
except Exception:
return invoke_anthropic_chain(topic) # noqa: F821
if __name__ == '__main__':
print(invoke_chain_with_fallback("ice cream"))
|
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatAnthropic
from langchain_community.chat_models import ChatOpenAI
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}")
output_parser = StrOutputParser()
anthropic = ChatAnthropic(model="claude-2")
anthropic_chain = (
{"topic": RunnablePassthrough()}
| prompt
| anthropic
| output_parser
)
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
fallback_chain = chain.with_fallbacks([anthropic_chain])
if __name__ == "__main__":
print(fallback_chain.invoke("ice cream"))
|